Back to Projects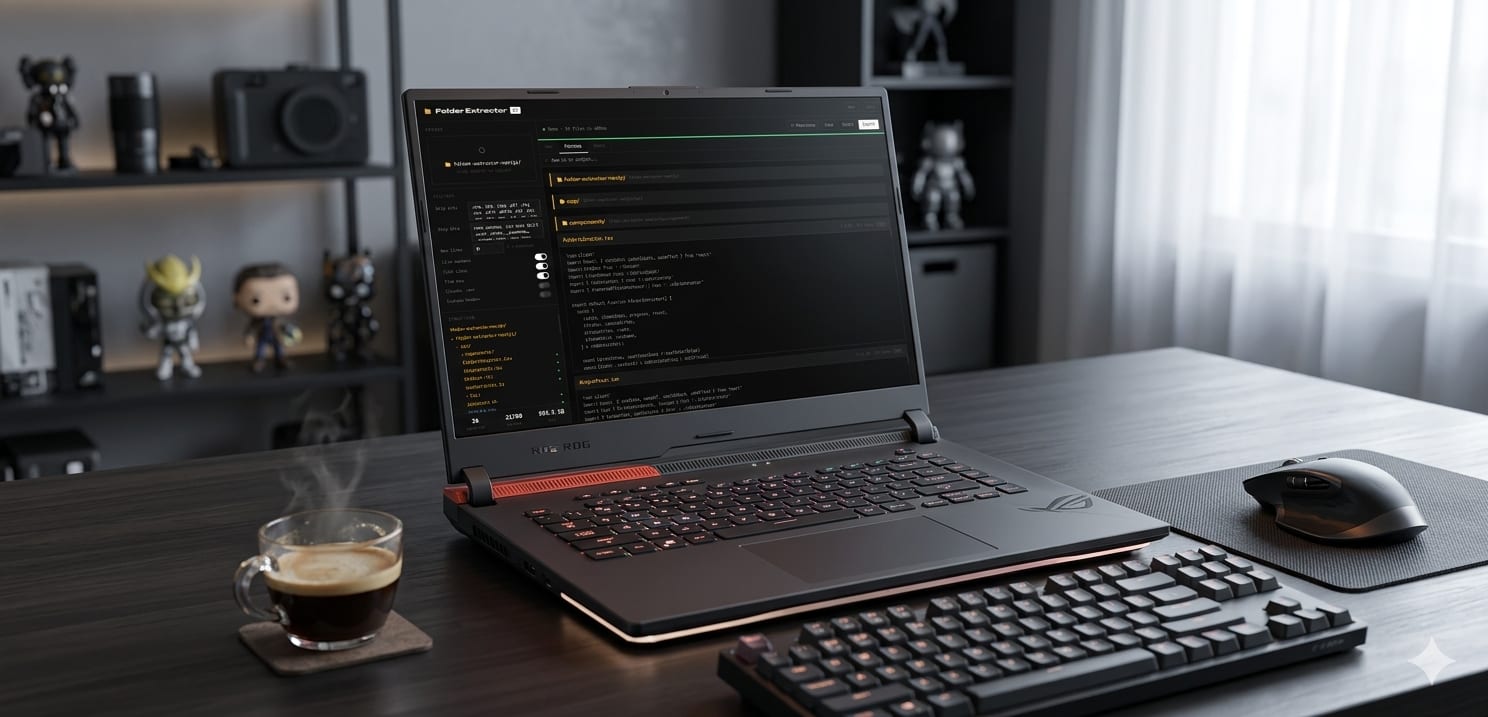
ReactNext.jsTailwind CSS
Folder Content Extractor
A zero-backend, browser-native developer utility that reads an entire folder, filters noise (node_modules, binaries, hidden files), builds a directory tree, and exports all file contents as a single structured TXT or JSON — designed specifically for feeding full codebases into AI context windows like Claude, GPT-4, and Gemini.
May 202678 views📷 4 photos
1 / 4
Introduction
Every developer who uses AI coding assistants hits the same wall: you want to give the model your full codebase as context, but there's no easy way to do it. You end up manually copying files one by one, or writing a hacky shell script that dumps everything into a text file with no structure. I built Folder Content Extractor to solve this properly — a browser-native tool that reads an entire folder, filters out the noise, builds a directory tree, and exports everything as a single structured document in one click.
No backend. No server. No file uploads. Everything happens in the browser using the File System Access API and FileReader — your code never leaves your machine.
What it does
Drop a folder (or click to browse), and the tool reads every file in the directory tree, applies your filter rules, and produces a formatted output document containing the directory structure and full file contents — ready to paste directly into an AI context window.
- Drag & drop anywhere — a global drag overlay activates whenever you drag a folder over the browser window, not just over a specific drop zone. Drop it anywhere on the page.
- Smart filtering — skip extensions (
.png .jpg .svg .lock .map), skip directories (node_modules .git dist .next), max line truncation, and toggles for hidden files,.envfiles, and binary files. - Directory tree map — generates an ASCII tree of the folder structure (the same style as the Unix
treecommand) and prepends it to the output. - Three output tabs — Raw (the full formatted text output), Preview (syntax-highlighted file cards grouped by folder), and Stats (file type breakdown with bar charts, largest file, longest file, processing time).
- Export as TXT or JSON — TXT gives a human-readable formatted document. JSON gives a structured array of file objects with path, name, extension, size, line count, and content — useful for programmatic processing.
- Search in output — debounced search bar that counts regex matches across the full output in real time.
- Reprocess — change a filter setting and reprocess the same folder instantly without re-selecting it.
- Sidebar tree view — live file tree in the sidebar with color-coded extensions and green dot indicators for extracted files.
Tech stack
- Next.js 14 (App Router) — framework and build toolchain. The entire tool is a single client component (
'use client') — Next.js is used for its build pipeline, file routing, and deployment on Vercel, not for SSR. - React 18 —
useState,useCallback,useEffect,useRef. No external state management. The entire extraction pipeline is managed by a single custom hook:useExtractor. - Custom CSS variables — no Tailwind, no UI framework. Every style is written with inline styles and a CSS variable design system (
--bg,--surface,--accent,--mono,--yellow,--green, etc.). This keeps the bundle lean and gives complete control over the terminal-aesthetic design. - FileReader API — reads file contents as text directly in the browser. Binary/unreadable files gracefully resolve to a placeholder string.
- FileSystem Entry API (webkitGetAsEntry) — used for drag-and-drop directory traversal. The
traverseFileSystemEntryfunction recursively walks the directory tree usingFileSystemDirectoryReader.readEntries(), handling the API's batched 100-entry limit by looping until the batch is exhausted. - Blob + URL.createObjectURL — client-side file export. TXT and JSON downloads are generated in-browser with no server round-trip.
- Vercel — zero-config deployment.
Architecture
The codebase is split into four layers that map cleanly to separation of concerns:
lib/extractor.ts → all pure logic: types, helpers, filtering, tree building,
file reading, raw output formatting
useExtractor.ts → React hook: state machine, orchestrates the extraction pipeline
FolderExtractor.tsx → root component: layout, global drag, toast, export handlers
Sidebar.tsx → drop zone, filter controls, tree view, stats footer
OutputPanel.tsx → tabs (raw/preview/stats), search, action buttonsThe lib/extractor.ts file is deliberately framework-agnostic pure TypeScript — no React imports, no DOM dependencies. Every function in it is independently testable. The React layer in useExtractor.ts is the only place that touches state.
The extraction pipeline
When files are submitted (via drop or file input), useExtractor runs the following pipeline:
1. Sort all files by relative path (alphabetical, stable order)
2. Partition into toProcess / skipped using shouldSkipFile()
3. Build a TreeNode structure from toProcess file paths
4. Walk the tree depth-first, yielding every 20 files to keep the UI responsive
5. For each file: readFileAsText() → split lines → apply maxLines truncation → push FileSection
6. For each directory node: push FolderSection with depth for indent rendering
7. buildRawOutput() assembles the final formatted string from all sections
8. Set result state → UI re-renders with raw output, preview, and statsThe await new Promise(r => setTimeout(r, 0)) yield every 20 files is the key trick that keeps the progress bar and status text updating during large folder processing — without it, JavaScript's single-threaded nature would freeze the UI until the entire pipeline completes.
Directory traversal for drag & drop
Drag-and-drop folder reading requires the FileSystem Entry API — the standard e.dataTransfer.files doesn't recurse into subdirectories. The traverseFileSystemEntry function handles this:
async function traverseFileSystemEntry(entry, path = '') {
if (entry.isFile) {
// Wrap File with _relativePath for consistent path resolution
} else if (entry.isDirectory) {
const reader = entry.createReader()
// Loop readEntries() until empty — API returns max 100 entries per call
const readAll = async () => {
reader.readEntries(async entries => {
if (entries.length === 0) { resolve(); return }
const nested = await Promise.all(entries.map(e => traverseFileSystemEntry(e, ...)))
all.push(...nested.flat())
await readAll() // recurse until batch is empty
})
}
}
}The recursive readAll() loop is necessary because FileSystemDirectoryReader.readEntries() returns a maximum of 100 entries per call — for directories with more than 100 children, you must call it repeatedly until it returns an empty array. Missing this detail is a common bug in drag-and-drop file tree implementations.
File filtering
The shouldSkipFile function resolves the full relative path of each file and applies four independent filter rules in order: hidden file detection (dotfiles, excluding .env which has its own toggle), .env file exclusion, directory segment matching (checks every path part against the skip-dirs list), and extension matching (suffix check against the skip-exts list). All comparisons are lowercase-normalized to handle case-insensitive file systems correctly.
The default skip list covers the most common noise in a web project: node_modules, .git, dist, build, .next, .cache, __pycache__, and binary/asset extensions like .png .jpg .svg .woff .lock .map .zip. Users can edit both lists directly in the sidebar.
Output format
The raw output format is designed to be both human-readable and maximally parseable by AI models. It uses box-drawing characters for visual structure and consistent delimiters that a language model can reliably pattern-match:
╔════════════════════════════════════════════════════════════╗
║ FOLDER EXTRACTOR · v3.0
║ Generated : 5/5/2026, 1:18:01 AM
║ Root : my-project/
║ Extracted : 47 files
║ Skipped : 1,203 files
║ Total Size: 284.5 KB
║ Time : 312ms
╚════════════════════════════════════════════════════════════╝
┌────────────────────────────────────────────────────────────
│ DIRECTORY STRUCTURE
└────────────────────────────────────────────────────────────
my-project/
├── src/
│ ├── components/
│ │ └── Button.tsx
│ └── lib/
│ └── utils.ts
└── package.json
┌── src/components/Button.tsx · 2.1 KB · 68 lines
│
│ 1 import React from 'react'
│ 2 ...
└────────────────────────────────────────────────────────────The JSON export structures the same data as an array of file objects with path, name, ext, size, lines, and content — useful for piping into scripts or building custom tooling on top of the extraction output.
Extension color system
The getExtColor function maps file extensions to CSS variable color tokens: TypeScript/JavaScript files get --yellow, CSS/SCSS get --blue, HTML gets --orange, JSON/YAML get --green, Markdown gets --purple, Ruby/error files get --red. These colors are used consistently across the sidebar tree view, the preview tab file headers, and the stats tab extension breakdown bars — creating a visual language where file types are always recognizable at a glance.
Stats tab
After extraction, the Stats tab computes a full breakdown from the sections array: total files extracted, total files skipped, total size, processing time, largest file by byte size, longest file by line count, and a bar chart of file type distribution showing count and total size per extension. All computed client-side from the already-processed data — no additional parsing pass needed.
What I'd improve
- Web Worker for large codebases — for repositories with thousands of files, the extraction loop (even with
setTimeoutyields) runs on the main thread and can cause noticeable jank. Moving the pipeline into a Web Worker would keep the UI completely smooth regardless of folder size. - Highlight search matches in raw output — the search bar currently counts matches but doesn't scroll to or highlight them in the raw textarea. A proper find-in-file implementation (like VS Code's Ctrl+F) would make it much more useful.
- Syntax highlighting in preview tab — file contents in the Preview tab are rendered as plain text. Adding a lightweight syntax highlighter like Shiki or Prism would make the preview significantly more readable.
- Token count estimate — since the primary use case is feeding output into AI context windows, showing an estimated token count (using a tiktoken-compatible formula) alongside the character count would be genuinely useful for users managing context limits.
- Shareable filter presets — letting users save and share filter configurations (e.g., "Next.js project", "Python project", "monorepo") as URL-encoded presets would reduce setup friction for common project types.
Conclusion
Folder Content Extractor is a small tool that solves a real, specific problem — and solving it well required thinking carefully about browser APIs, UI responsiveness under load, output format design, and the exact workflow of a developer trying to give an AI model their codebase as context. Sometimes the most useful projects are the ones you build because you needed them yourself.
// Tech Stack
ReactNext.jsTailwind CSS